Interpret the base learner in Gradient Boosting Classifier
Gradient Boosting Classifier is a well-known ensemble model developed in different libraries such as Sklearn and XGBoost.
| kaggle | GitHub | Buy a coffee |
The base learner in the Sklearn model is Decision Regressor Tree which has its attributes. After training the model, you can use the base learner’s methods as well.
First, we have to import the model and train it over the dataset.
In the following, I used a predefined dataset from the Sklearn library.
import sklearn.datasets as dtX, y = dt.load_iris(return_X_y=True)
To train the model and evaluate it, one can use the stratified sampling method to have the same distribution in both training and test batches.
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
Now, it is time to build the Gradient Boosting Model from the Sklearn library.
from sklearn.ensemble import GradientBoostingClassifiermodel = GradientBoostingClassifier()model.fit(x_train, y_train)model.score(x_test, y_test)
As the focus of this review is the base learner, not the training of the ML model process, I used the default hyperparameters and trained it simply on the training batch, and tested it on the test.
Tree
So, where are the base learners and their attributes? For this case study, we have (100, 3) trees which means 100 trees for each class label. So, how to check the tree? You can see that all trees are stored in the following method.
model.estimators_
print(model.estimators_.shape)>>> (100, 3)
The first tree for the first-class label is;
model.estimators_[0][0]>>> DecisionTreeRegressor(criterion='friedman_mse', max_depth=3, random_state=RandomState(MT19937) at 0x21628DFAA40)
the .tree_ returns the trained tree
model.estimators_[0][0].tree_>>> <sklearn.tree._tree.Tree at 0x2166c7c2f80>
Draw the tree
You can also draw your tree with the following code
from sklearn.tree import plot_treetree = model.estimators_.reshape(-1)[1]plot_tree(tree)
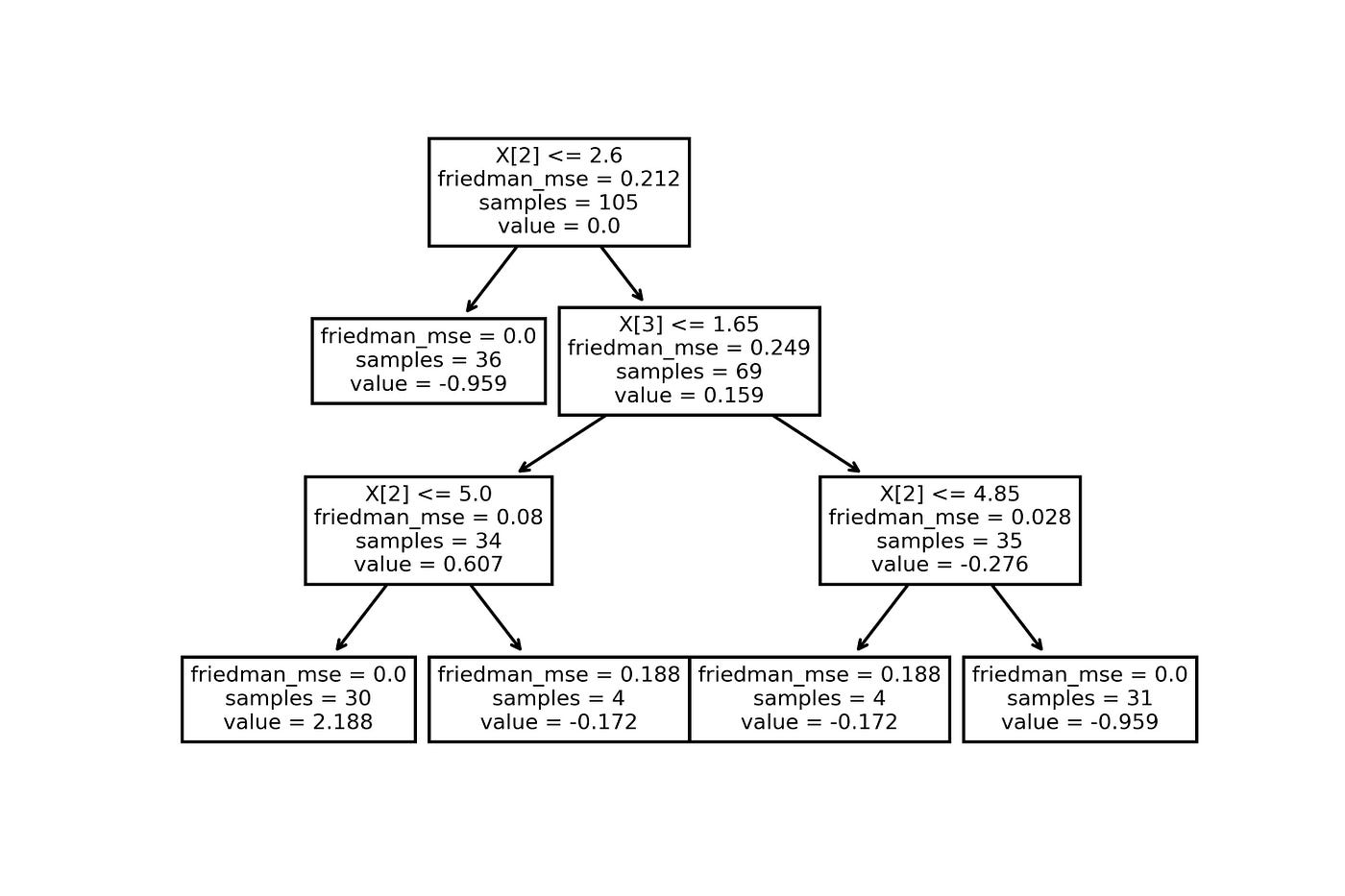
Leaves
Another question you might ask s that, what about the number of leaves.
Your answer is the following code.
tree.tree_.n_leaves
>>> 5The summation of all leaves would be
print(sum(tree.tree_.n_leaves for tree in model.estimators_.reshape(-1)))Tree’s Value
Returning the tree value by the following code
tree = model.estimators_[1][0]tree.tree_.value>>> array([[[-3.09980500e-05]], [[ 1.61886012e+00]], [[-3.06927659e-01]], [[-3.08667222e-01]], [[-9.63116480e-01]], [[-9.82423324e-01]], [[-3.05809369e-01]], [[-9.62883563e-01]], [[-9.59686381e-01]]])
Likewise, we know that we have nine nodes and also you can count it
tree.node_countIn the following, I stored the values, total nodes, right and left child’s nodes, features, and root nodes for the first tree of the first class.
tree = model.estimators_[0, 0].tree_values = tree.valuenodes = tree.node_countleft_child = tree.children_leftright_child = tree.children_rightfeature = tree.feature
Support the Author
To support the Author, you can buy a coffee for him.
| Buy a coffee |
